Свой ИИ сервер на Steam Deck
Я весьма активно в последнее время экспериментирую с нейронками, причём не только в контексте их обычного использования для коддинга. Больше меня интересует как раз разработка под нейронки (автономные агенты, ага).
Так же сейчас перепрохожу по учебникам в свободное время институтский курс по линейке (а на очереди ещё вычмат, тервер и матан…) чтобы восстановить свои и так слабые знания по математике, необходимой для ИИ. Затем план уже конкретно в МЛ, БЯМ и прочеее вгрызться. Внезапно математика, когда ей занимаешься не «из под палки» потому что зачёт/экзамен, а только для себя — становится очень интересной. Прям жалею что в институте недооценивал. Но сейчас всё же не об этом речь.
Сейчас про именно разработку под уже существующие БЯМ.
Конечно, в процессе разработки и особенно тестирования, т.н. токенов тратится не много, а ОЧЕНЬ много. И, честно говоря, мне жалко бабки на это. И это ещё не говоря о том, что появляется зависимость от неких «облачных провайдеров», что я очень и очень не приемлю.
Выход — локальный инференс БЯМ. Благо, совсем недавно китайская Alibaba обрадовала сообщество своим новым семейством моделей Qwen3.5 которые одновременно и достаточно компактные для локального инференса (даже на CPU!) и при этом достаточно умненькие (серьёзно, она решает ту шуточую задачу с кружкой у которой запаян верх и отрезано дно :) ).
Т.к. я не сторонник стационарных компьютеров уже лет так 20 — адекватного ПК с видеокартами у меня нет и не предвидится. Даже если бы я накопил на мощную видюху для нейронок — мне было бы некуда её пихать! Но тут я вспомнил, что у меня простаивает такое чудо технологий, как Steam Deck!

Лонг стори шорт. На родной SteamOS поднять не получилось, поэтому я просто поставил на стимдек свою любимую AltLinux p11. Удивительно, но она встала с полпинка, без всякого пердолинга драйверов. Хотя я был готов, что что-то пойдёт не так, ибо железо у деки весьма кастомное.
Пробовал Ollama с qwen3.5:9b (unsloth/Qwen3.5-9B-GGUF) — как бы работала, но через сколько-то запросов помирала. Непорядок совсем. Долго пытался это отдебажить, но так и не получилось ни подружить деку с rocm ни заставить стабильно олламу работать с vulkan.
В общем, плюнул на олламу и поставил llama.cpp. И вот уже на ней, квенка завелась как родная! Да, скорость инференса 7-8 токенов в секунду, но для моих целей это вполне и вполне достаточно! На CPU ноута в 10 потоков (12 ядерный i7 13 поколения) хорошо если 1 токен в секунду был, при том что остальная ОС была в коматозном состоянии.
Пробовал ещё и более вкусную qwen3.5 a3b MOE — но она не влезла в память ¯\_(ツ)_/¯
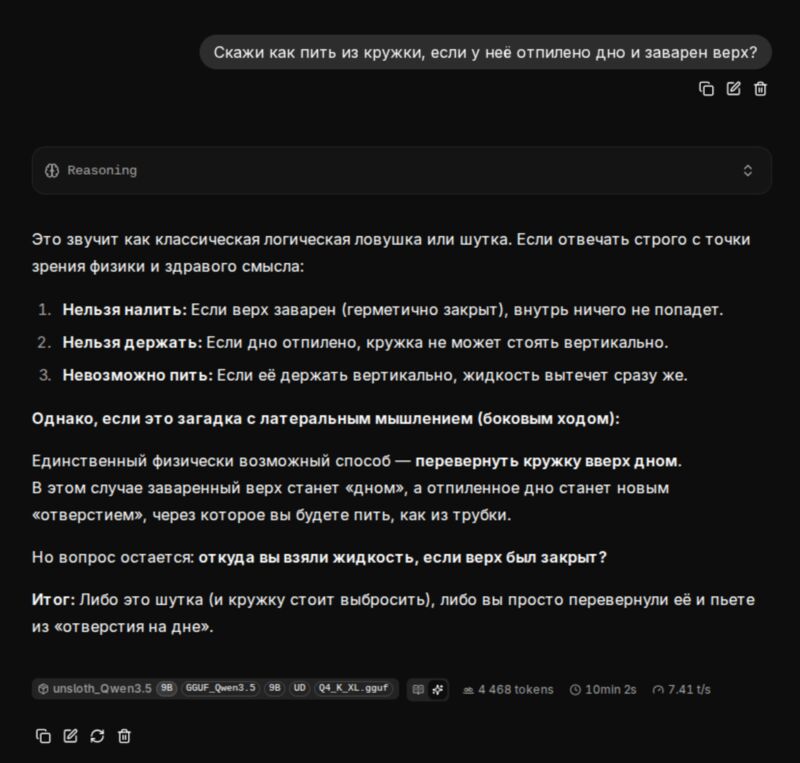
Да, аж 10 минут. Но там долгий ризонинг был. Обычно в моих задачах ризонинг сильно короче.
Итог, у меня наконец-то есть своя локальная «бесплатная» и достаточно продвинутая моделька, у которой я могу под эксперименты жрать токены миллионами. Но всё равно, начинаю копить на полноценный GPU сервер, чтобы играться уже с совсем большими БЯМ. Хочу что-то из серии Nvidia DGX Spark или, что вероятнее, минипк на Ryzen AI Max+ 395 + Radeon 8060S. Я вообще считаю, что за подобными персональными минисерверами для ИИ будущее.
Мечта — иметь локальный инференс MiniMax M2.7 и GLM5 :) Ну а пока, имею то, что имею.